

Summary
This tutorial describes how to import historical trial data into the Breeding Management System database using the Data Import Wizard. This tutorial begins with a newly created empty maize program database. Once historical variables are mapped to the BMS ontology, subsequent historical trial data will import seamlessly.
- Summary
- Introduction
- Import Germplasm List
- Format Historical Data
- Data Import Tool
- Complete Mapping
- Retrieve Dataset
- Related Materials
Introduction
The Data Import Wizard facilitates the formatting of historical trial data, making the data recognizable to the Breeding Management System (BMS) by matching trial descriptors to the standardized crop ontology. We recommend using the Data Import Wizard when the trial data is formatted differently than then .xls files created by the BMS or the related older IBFieldbook application.
Import Germplasm List
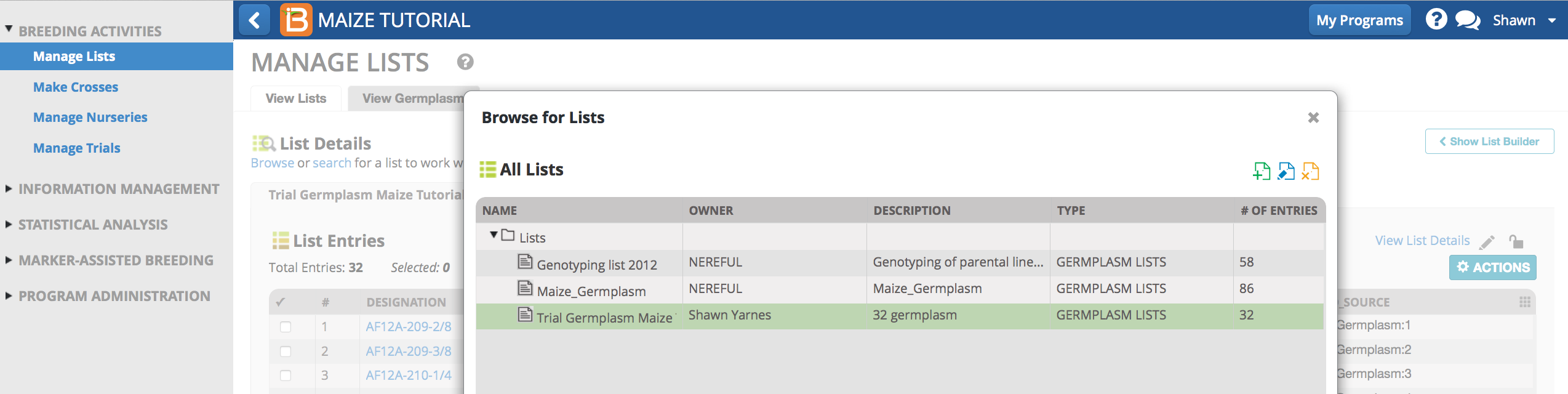
The first step for trial data import is to match or assign trial germplasm BMS-specific germplasm identifiers (GIDs) by importing the trial germplasm list (.xls) (See more on Germplasm Import)
- From Manage Lists, select import germplasm. Browse and upload the example trial germplasm list file. This is same germplasm list used in the previous trial design tutorial. If you have already uploaded this list, you can skip the data import steps in this tutorial.
Example File: Trial Germplasm (.xls)
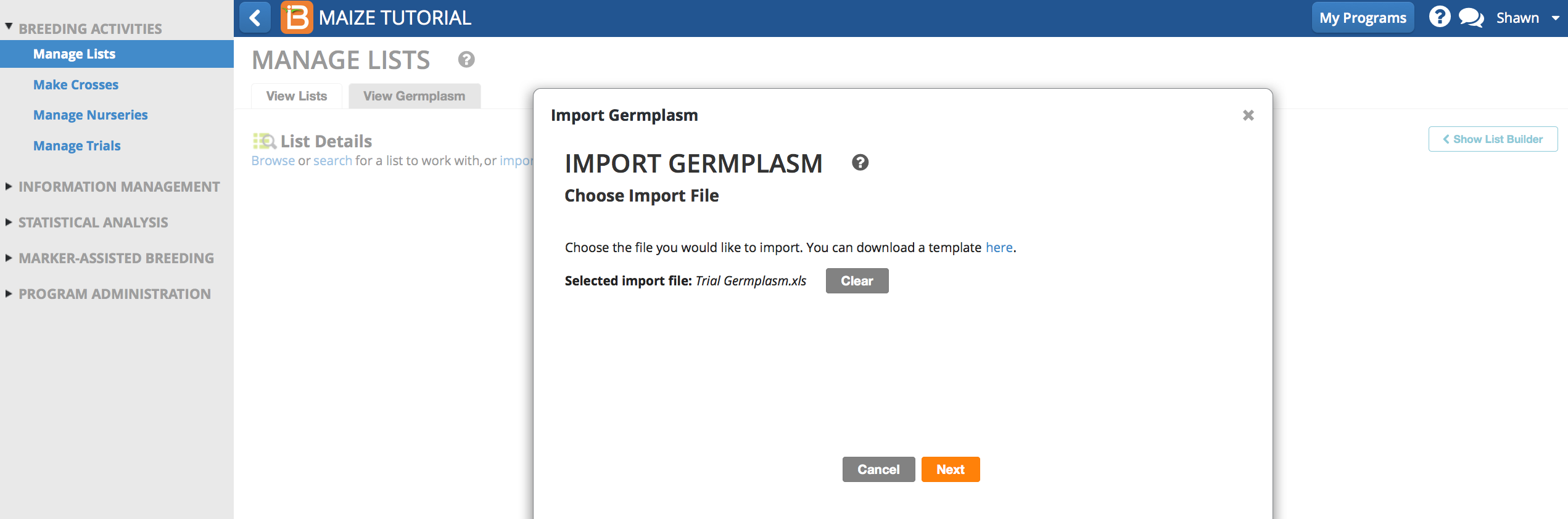
- Specify germplasm details.
- Breeding Method: Unknown generative method
- Location: Unknown
- Seed Storage Location: Unknown
- Date: Today's date default
- Name Type: Line Name
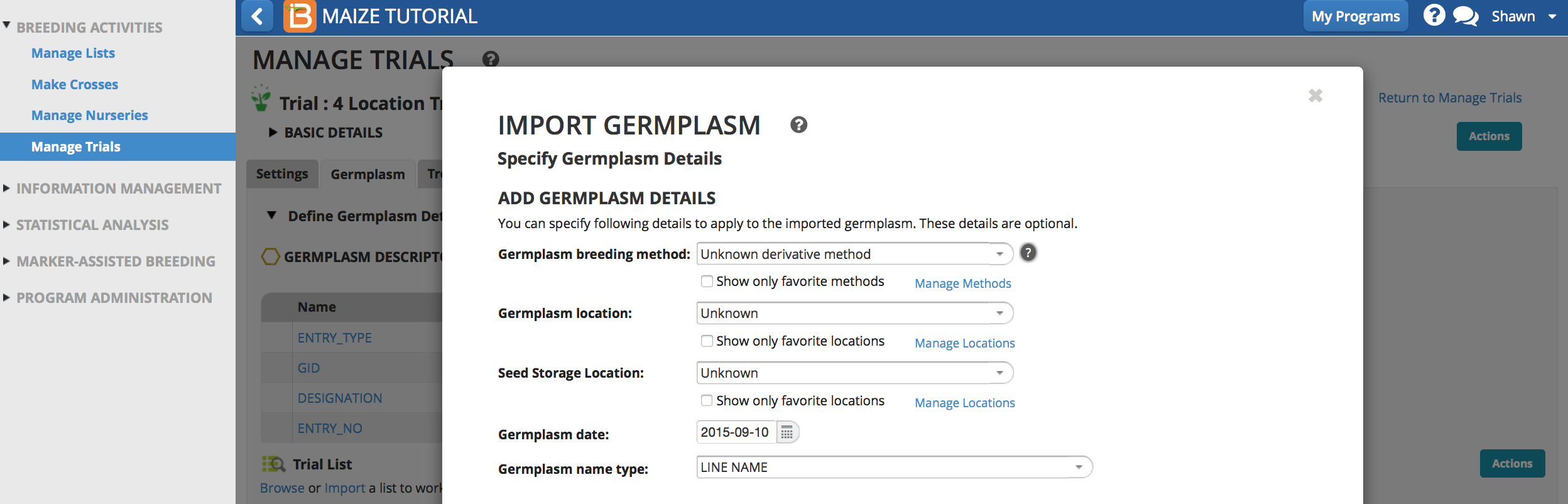
- Set the pedigree options to select existing germplasm whenever found and automatically accept single matches whenever found. Select Finish.
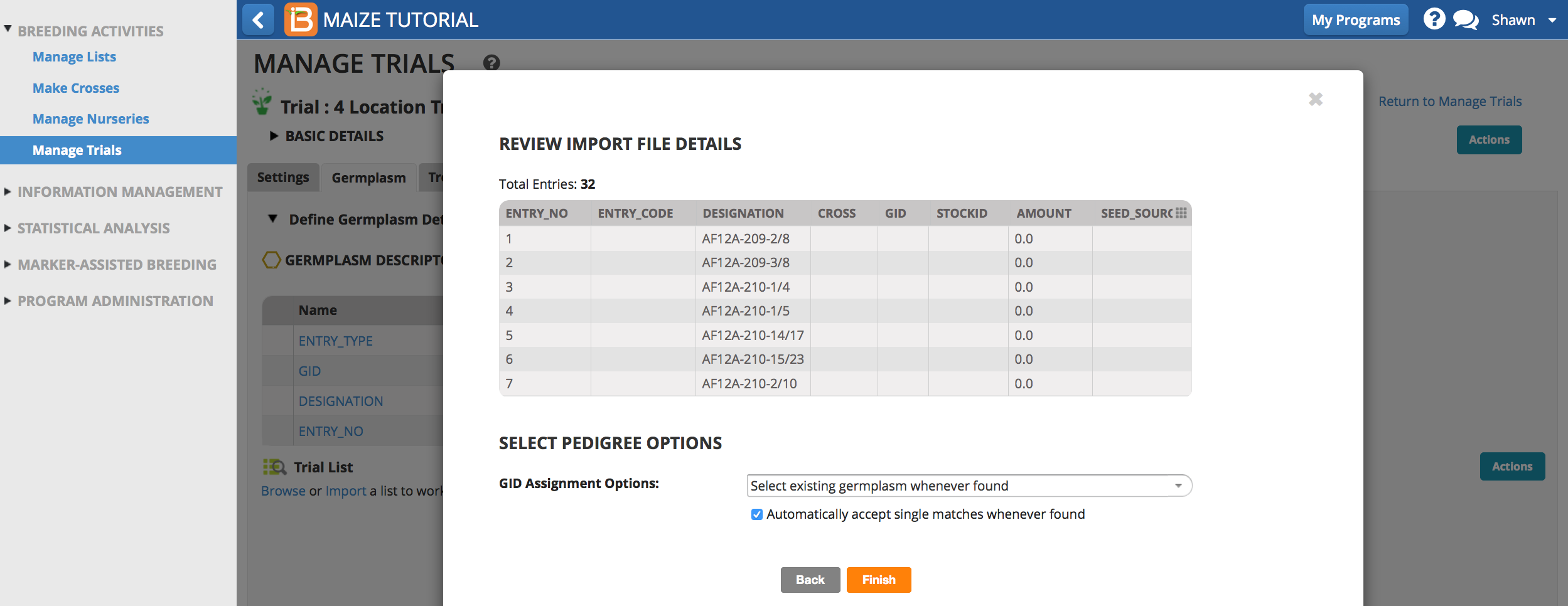
- Save the list with the imported list details.
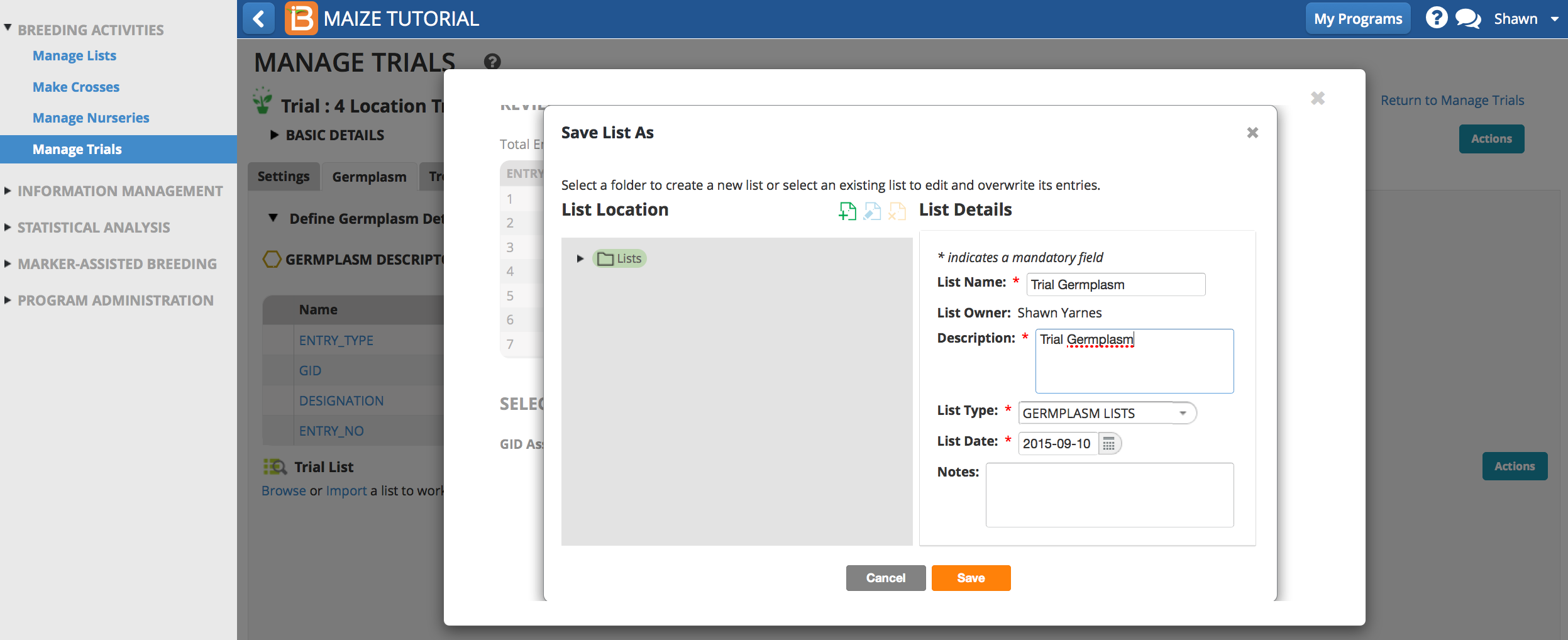
The 32 germplasm entries associated with the historical trial data are now available as a list within the BMS database. The germplasm have been assigned GIDs that will be matched to historical trial data during import.
Format Historical Data
The provided historical trial data is not formatted for the BMS. Although the Data Import Wizard will walk users through most steps of data mapping, it does have minor formatting requirements. To get started, 3 columns of data need be formatted with the following header names to match the ontology:
- TRIAL_INSTANCE
- PLOT_NO
- ENTRY_NO
The Data Import Wizard also requires that the import file contains two worksheets, titled 'Observation' and 'Description'.
- Open the example file of historical trial data in Excel.
Example File: Unformatted Maize Historical Trial Dataset (.xls)
Match 3 Header Names to Ontology
- In Excel, change the header names to match the ontology terms defined in the BMS.
- TRIAL to TRIAL_INSTANCE
- PLOT to PLOT_NO
- ENTRY to ENTRY_NO
 ?
?
Observation & Description Worksheets
- Change the title of Sheet 1, which contains all of the observations, to 'Observation'. Select the + tab to create a new sheet titled 'Description'. Drag and drop the empty Description sheet to place it before the Observation sheet. Save the file as Formatted Historical Trial Data.xls.
.png)
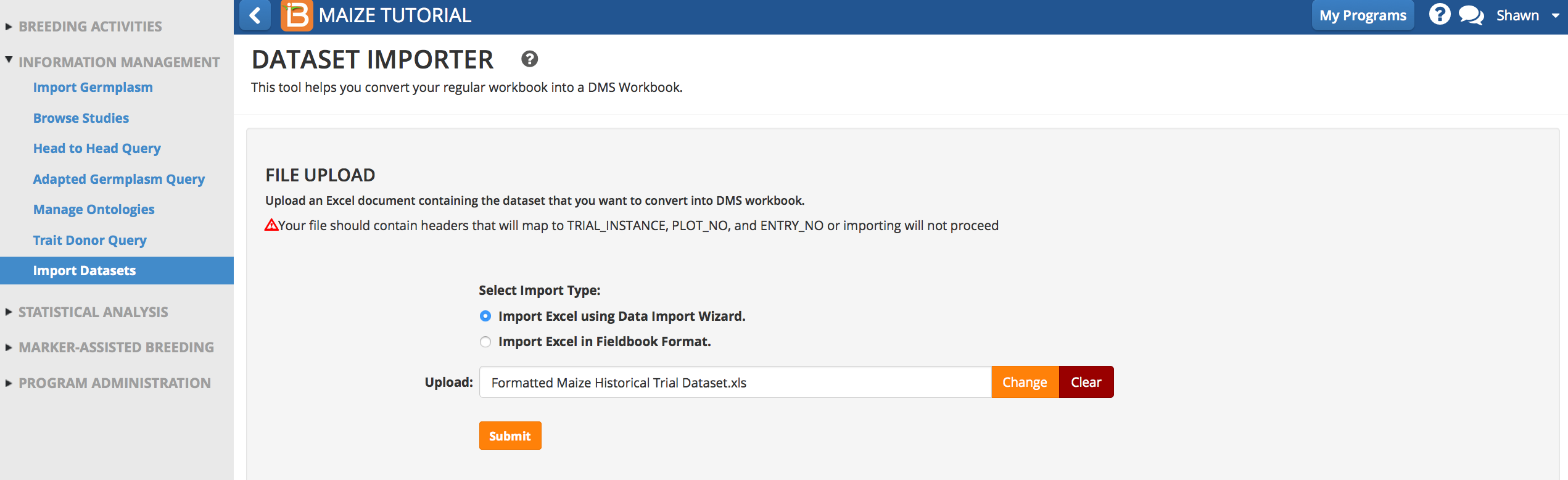
Data Import Tool
- Access the Data Import Tool from under Program Administration. Import data using Data Import Wizard. Browse and upload Formatted Historical Data.xls. Submit.
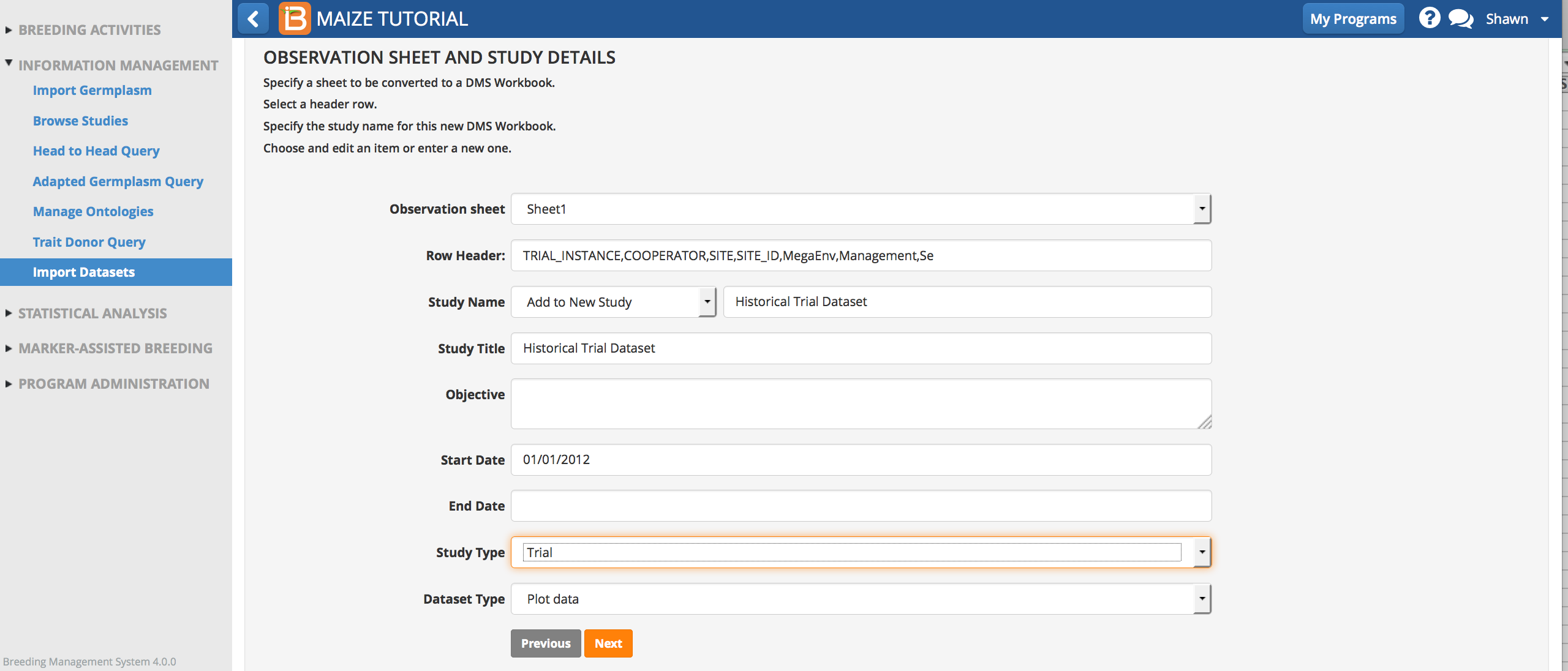
- Establish the observation sheet and study details and select Next.
- Observation Sheet: Observation sheet will be selected automatically
- Row Header: Row # 1 (TRIAL_INSTANCE, ….)
- Study Name: Historical Trial Dataset
- Study Title: Historical Trial Dataset
- Objective: Empty
- Start Date: 01/01/2012
- End Date: 06/01/2012
- Study Type: Trial
- Dataset Type: Plot data
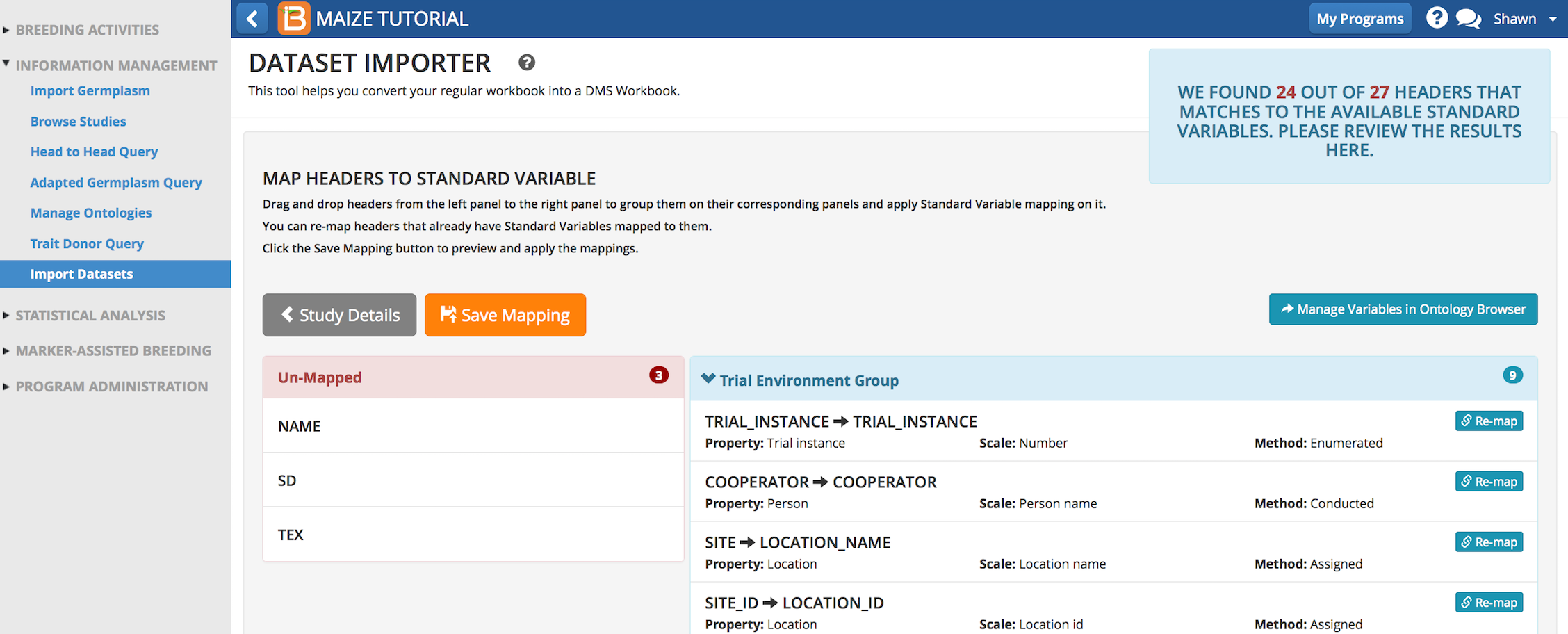
The Data Import Wizard was able to map 24 of the 27 header variables. The next steps are to review the 24 mapped variables and assist the mapping of the 3 unmapped variables.
The dataset importer groups trial variables into 4 categories.
- Trial Environment Group: Details about management and location of trial
- Germplasm Entry Group: Details about germplasm, such as name and entry number
- Trial Design Group: Details relating to experimental design, such as; plots, blocks, and replicates
- Variate Group: Details relating to phenotypic measurements
Review Mapped Variables
The Data Import Wizard attempts to match historical variable names to BMS ontology terms. A person with a working knowledge of the original trial will need to confirm that automatic matching is correct
- A review all 24 mapped variables confirms that they have been correctly matched to BMS ontology terms.
Assist Mapping of Un-Mapped Variables
Review the 3 un-mapped variables. Dragging and dropping variables into their respective variable groups begins the mapping process. Variables that do not exist in the ontology need to be added (see Manage Ontology).
Re-Map Variable: NAME
NAME describe the trial germplasm and belong to the Germplasm Entry Group.
- Drag NAME to the Germplasm Entry Group to launch the mapping. Apply mapping.
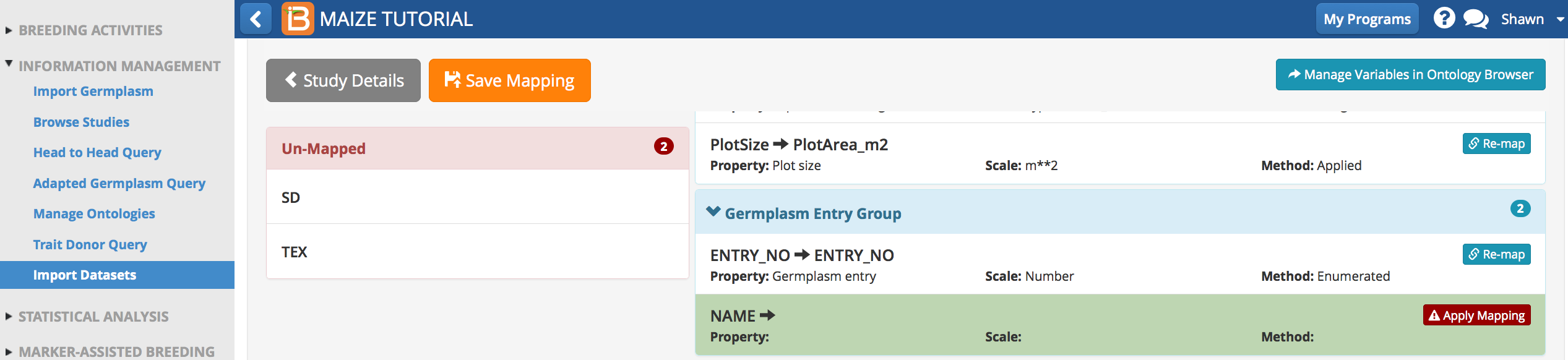
- Search for ontology terms related to ‘germplasm’. Select the term ‘DESIGNATION’ as a match for ‘NAME’.
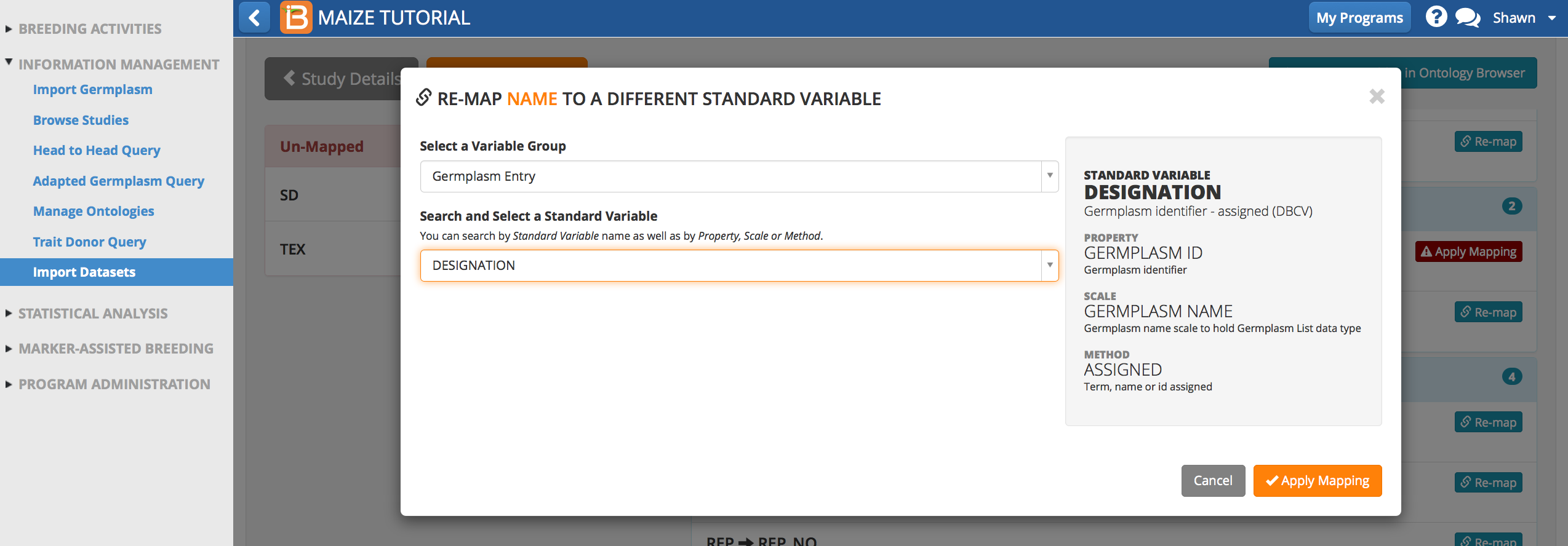
NAME is now mapped to the ontology term, DESIGNATION.
Re-Map Variable: SD
SD belongs to the Variate Group, because it is a phenotypic measure of days to silking.
- Drag SD to the Variate Group to launch the mapping. Search "silk" as a standard variable. Select DTS_days__obs and Apply Mapping.
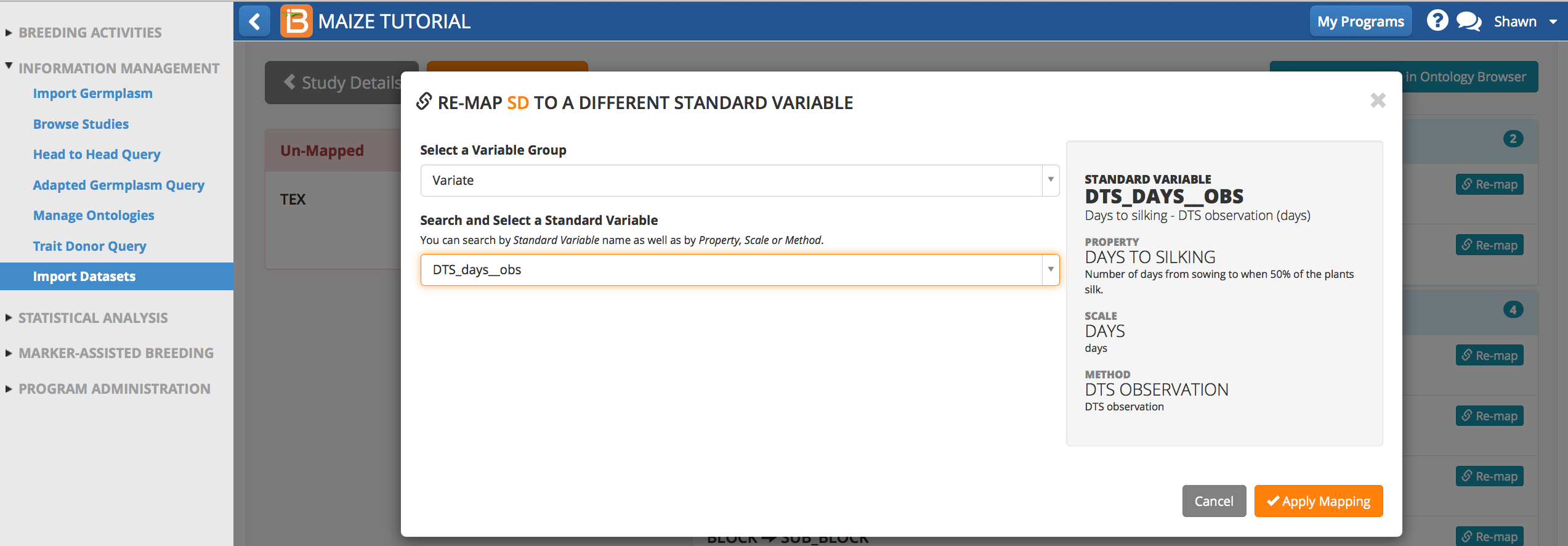
SD is now matched to the ontology term, DTS_days__obs.
Re-Map Variable: TEX
TEX belongs to the Variate Group, because it is a phenotypic measure of grain texture.
- Drag TEX to the Variate Group to launch the mapping. Search for "texture" as a standard variable. Select TEX_1_5, which is a categorical measurement of grain texture on a scale of 1 to 5. Apply Mapping.
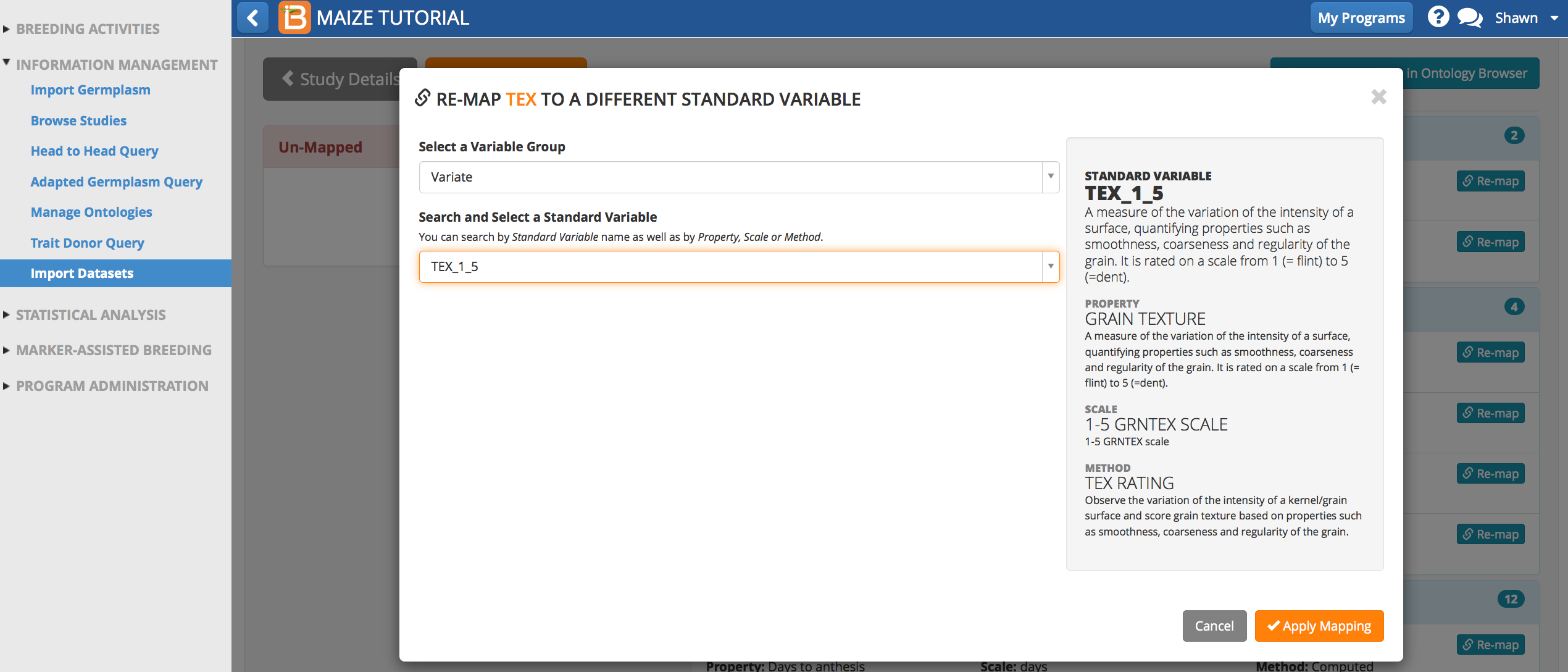
TEX is now matched to the ontology term, TEX_1_5.
Complete Mapping
- Once all of the traits are mapped and reviewed, select Save Mapping.
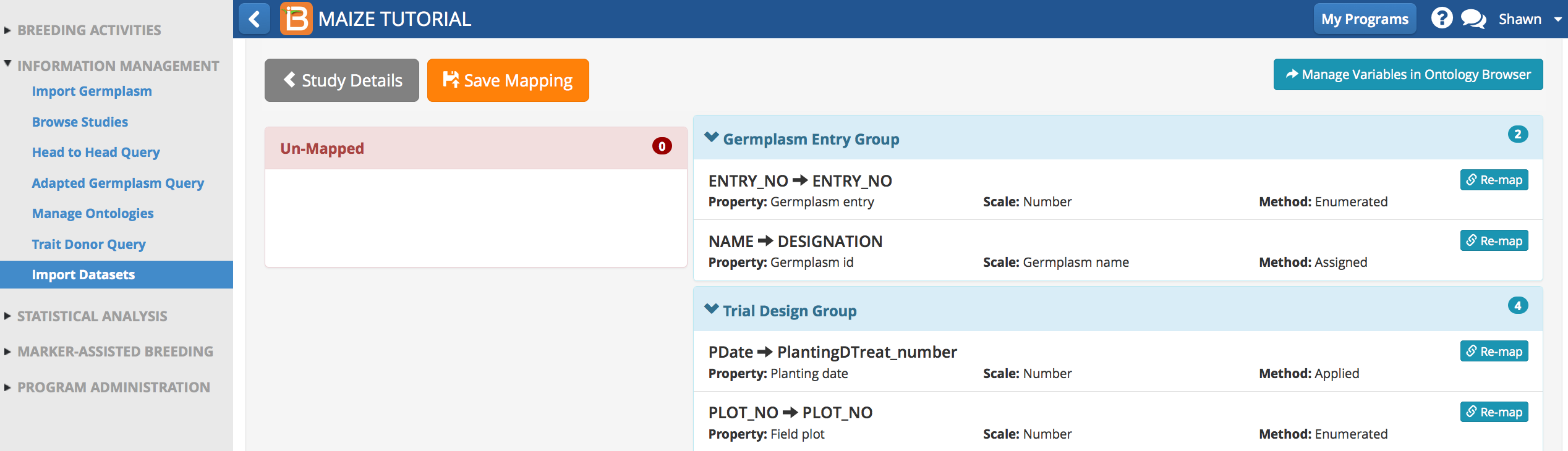
- Mistakes were made in the automatic mapping of 3 trial environment variables. Select Re-Do Header Mapping to manually differentiate these variables.
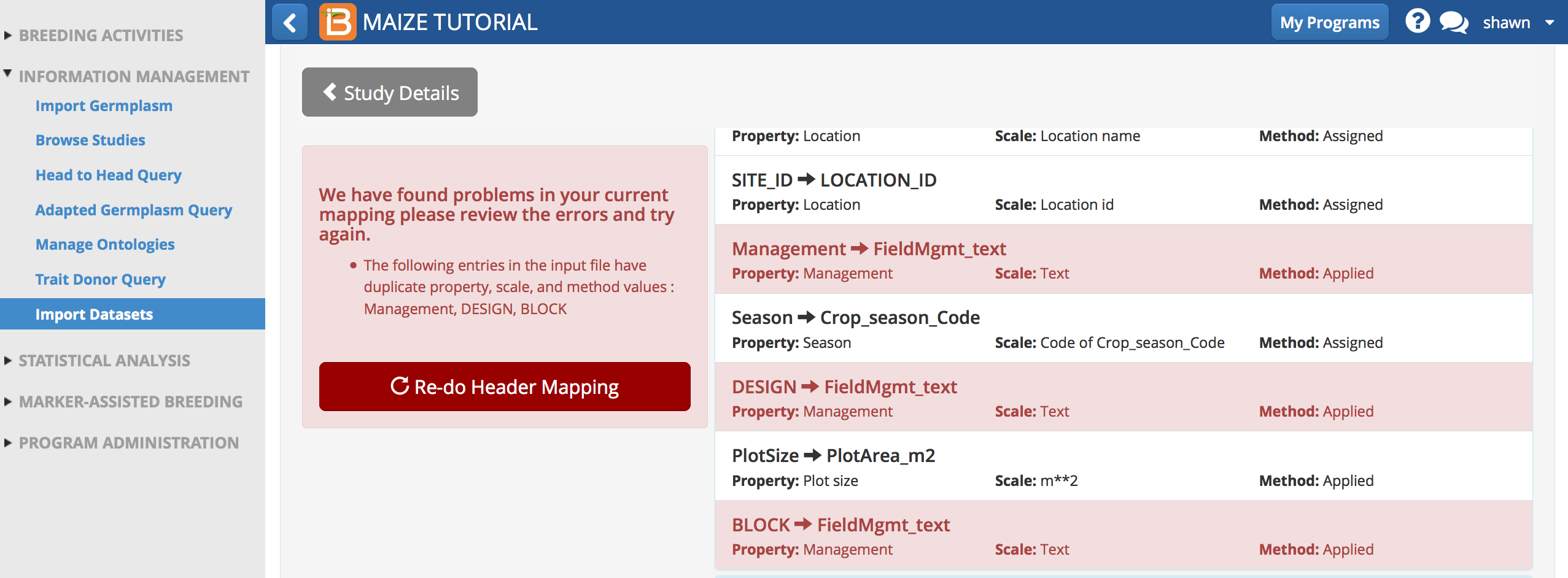
- Three traits were mapped to "FieldMgmnt_text". Only "Management" is correctly described by "FieldMgmnt_text". Remap DESIGN and BLOCK to the correct ontology terms and Save.
- DESIGN = EXPT_DESIGN
- BLOCK = BLOCK_ID
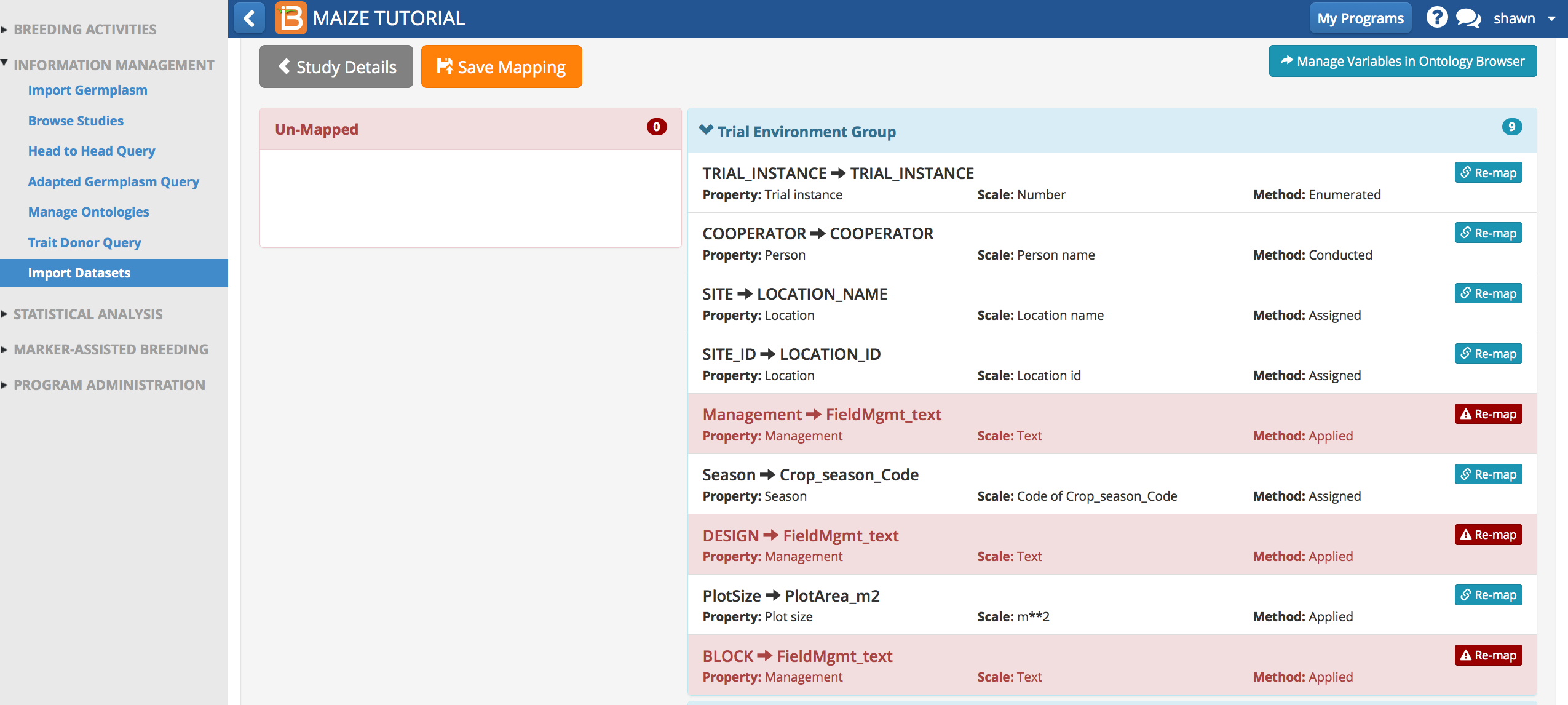
- Review the mapping and Confirm Header Mapping.
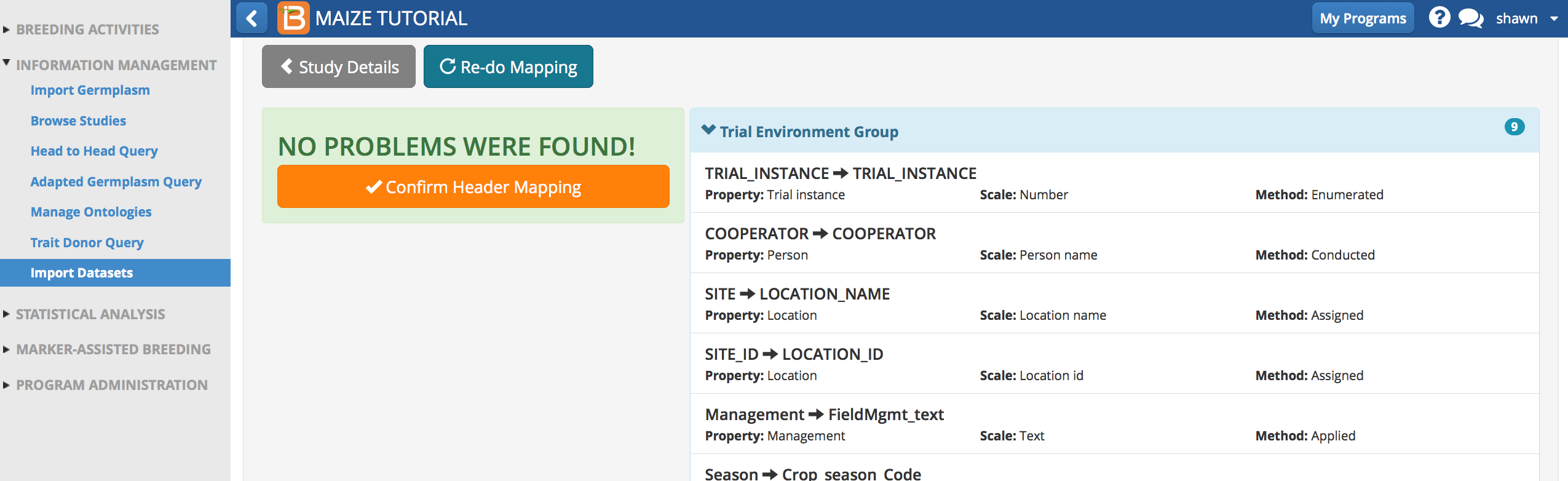
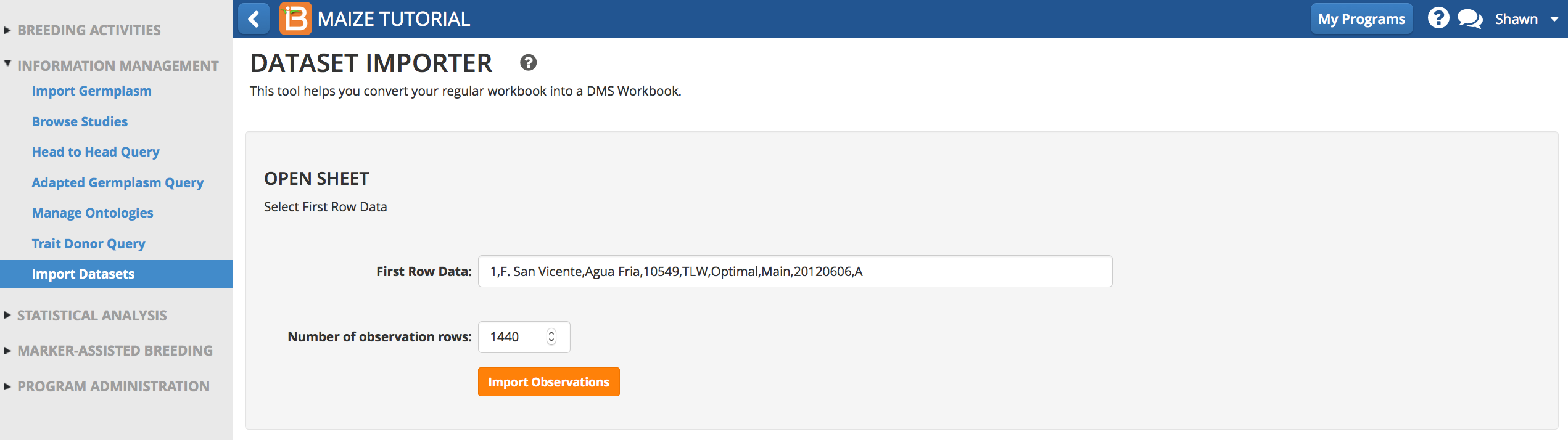
- Specify the first row of data. The number of observation rows will be counted automatically. Select Import Observations.
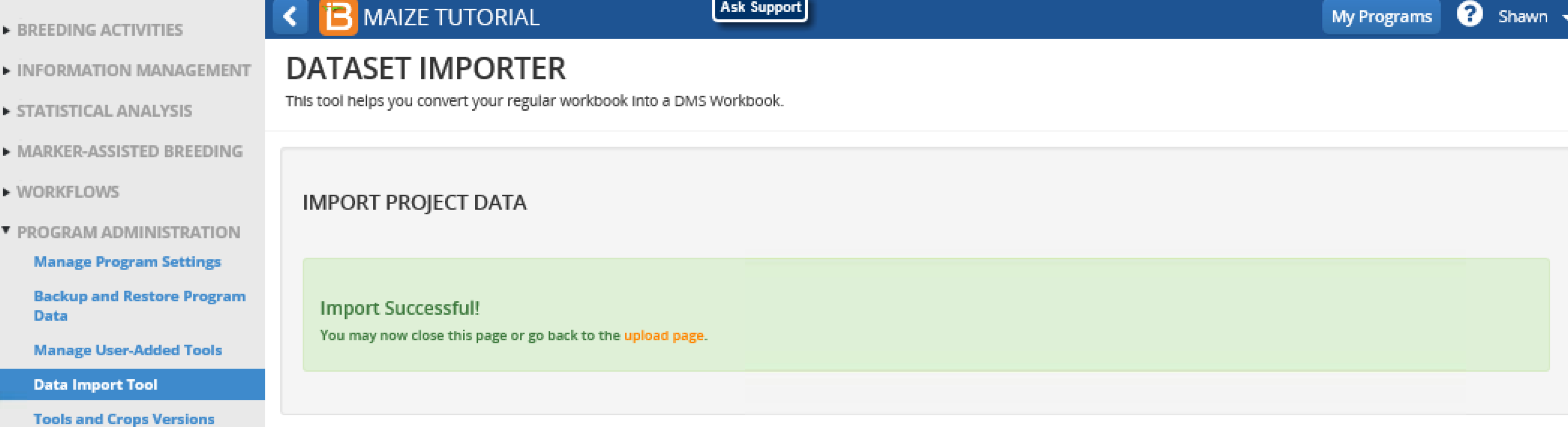
A notification appears when import is successful.
Retrieve Dataset
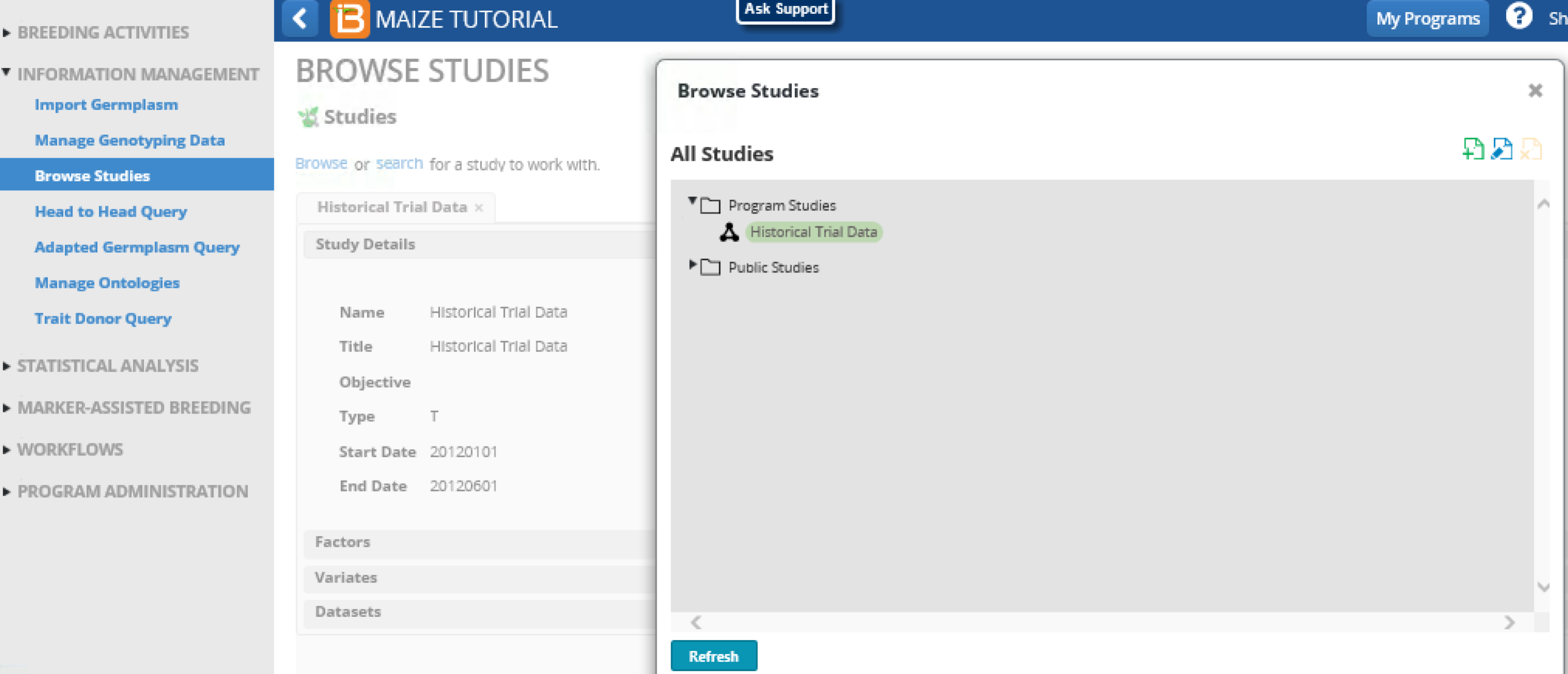
After successful import, Historical Trial Data is available for review and for use in Single Site Statistical analysis.
- From Information Management, select Browse Studies. Browse for the newly imported study, Historical Trial Data.
Related Materials
Manual: Data Import Tool
Manual: Manage Ontology
Maize Tutorial: Trial Design & Data Collection
Maize Tutorial: Single Site Analysis: 4 Location Batch
Maize Tutorial: Multi-Site (GxE) Analysis
The Integrated Breeding Platform (IBP) is jointly funded by: the Bill and Melinda Gates Foundation, the European Commission, United Kingdom's Department for International Development, CGIAR, the Swiss Agency for Development and Cooperation, and the CGIAR Fund Council. Coordinated by the Generation Challenge Program the Integrated Breeding Platform represents a diverse group of partners; including CGIAR Centers, national agricultural research institutes, and universities.
Maize ?demonstration data was provided by Mike Olsen at CIMMYT International Maize and Wheat Improvement Center. These data have been adapted for training purposes. Any misrepresentation of the raw breeding data is the solely the responsibility of the IBP.

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License?
