

 ?
?
Image Credit: http://phymap.ucdavis.edu/cowpea/
Contributors
Shawn Yarnes a, Darren Murray b, Roger Payne b & Zhengzheng Zhang b
?a The Integrated Breeding Platform, b VSN International Ltd
Summary
The tutorial describes the single site analysis of three locations of data from a multisite cowpea field trial using a completely randomized block design with 3 replicates per location.
- Restore from previous tutorial
- Introduction
- Select Dataset to Analyze
- Run Analysis
- Analysis Results
- References
Restore from Previous Tutorial
Screenshots and activities in this tutorial build upon work preformed in previous tutorials.
- If you are not following the cowpea tutorials in sequence, restore the Cowpea Tutorial database (.sql) to the end of the previous tutorial, Design and Management of Field Trials, to match database contents with current tutorial.
Restoration File?: Restore Cowpea Tutorial 7.0 (.sql)
Introduction
Breeding View’s single site analysis uses mixed models to account for extraneous sources of variation in breeding trials, including replicates and incomplete blocks. The single site analysis produces adjusted means, best linear unbiased estimators and best linear unbiased predictors (BLUEs and BLUPs) per genotype. These adjusted means can be used within a genotype by environment (GxE) analysis or QTL (quantitative trait loci) analysis pipeline.
Select Dataset to Analyze
- Open Single Site Analysis from the Statistical Analysis menu of the Workbench. Browse to find the 3 Site Trial dataset.
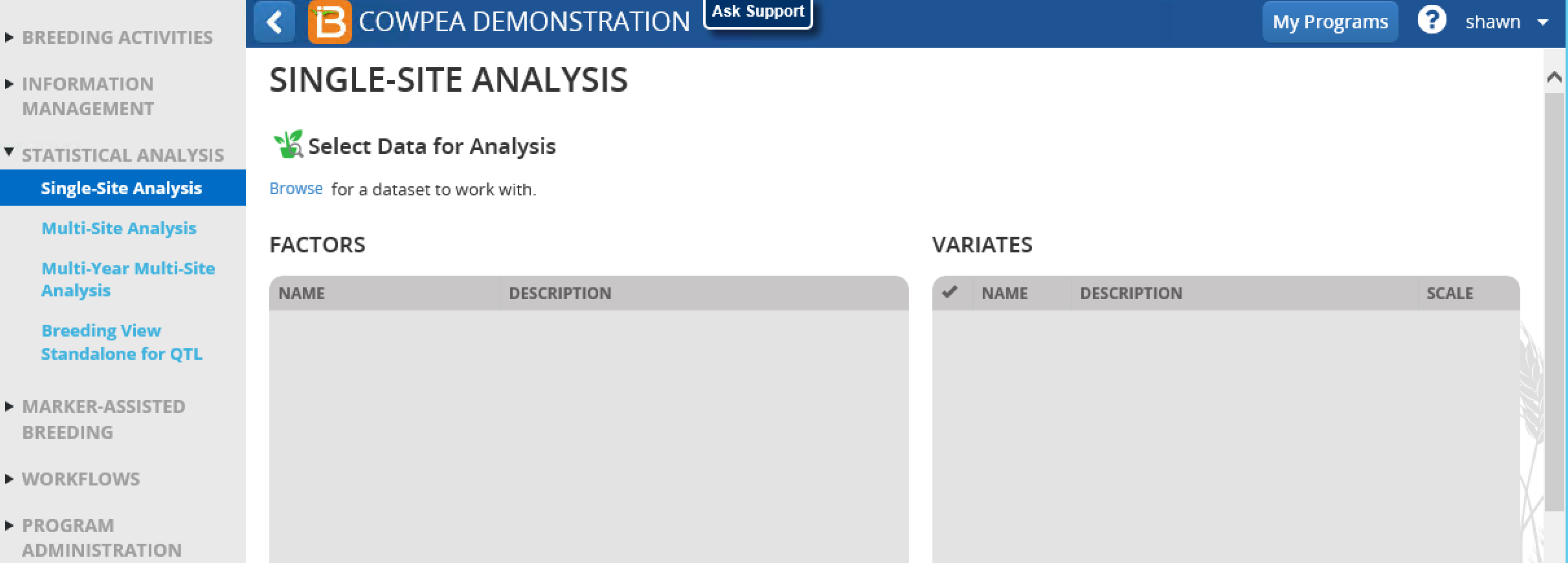
- Navigate to the PLOTDATA file within the 3 Site Trial folder and highlight the Measurement Effect dataset.
.png)
Specify Data For Analysis
- Review the factors and traits. You will recall that only two traits, MAT50 and SDW100, were measured for this trial, so deselect all traits represented by empty data columns. With only these two traits checked, select next.
.png)
- Specify analysis conditions.
- Use the default analysis name.
- Select Randomized Block Design for the design type.
- The factor that defines environment is SITE.
- Select all three locations to perform individual single site analysis on each location.
- REP is the factor in this dataset that defines replications. DESIGNATION defines the germplasm factor to be used in the analysis.
- Click Run Breeding View to launch the breeding view application.
 ?
?
Run Analysis
Single site analysis is database integrated. When the Breeding View application launches the analysis conditions and data are loaded. Notice that the three locations and both traits are selected. Right click on any trait or location to deselect from the analysis. When a project has been created or opened, a visual representation of the analytical pipeline is displayed in the Analysis Pipeline tab. The analysis pipeline includes a set of connected nodes, which can be used to run and configure pipelines.
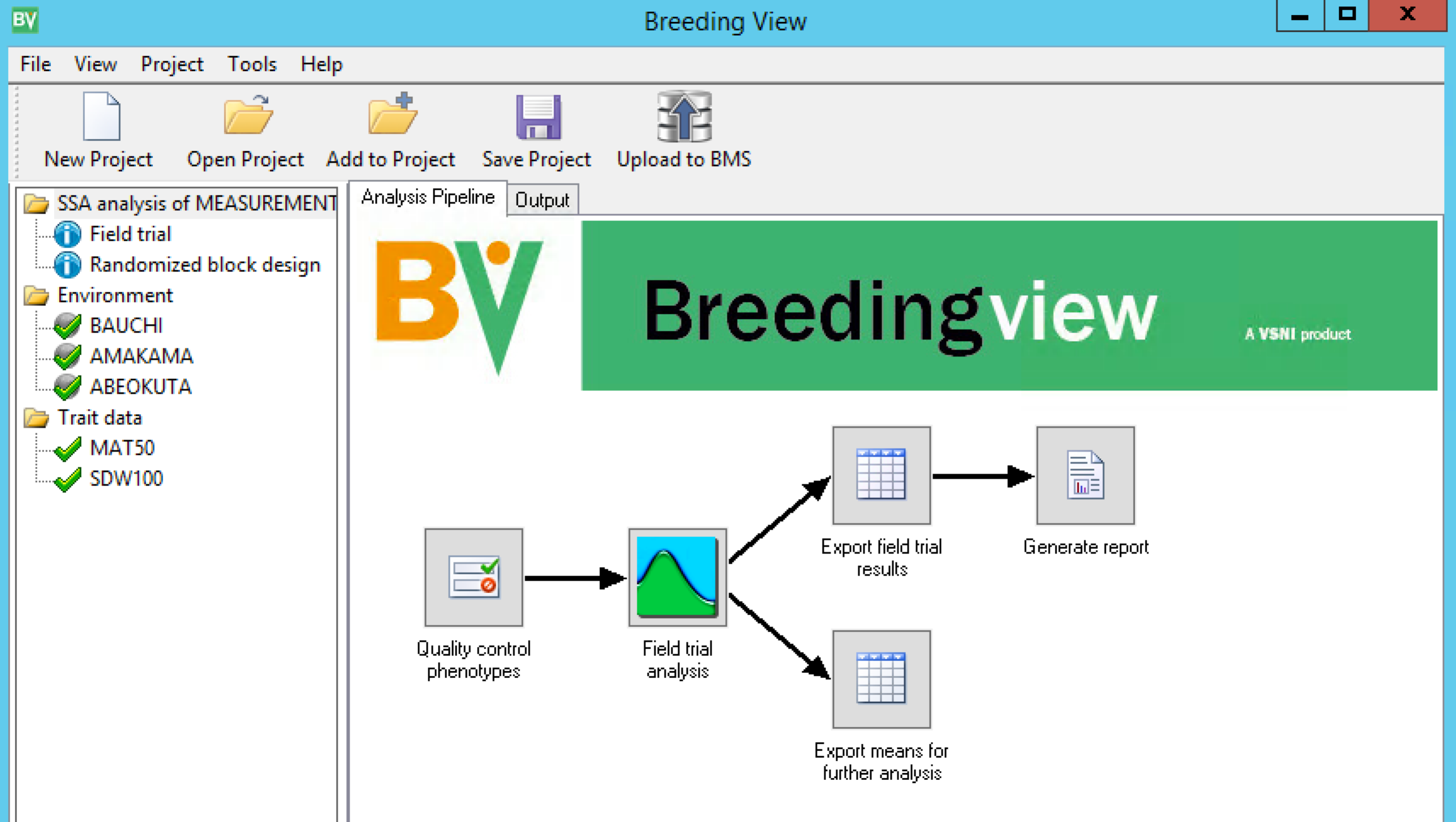
Description of Nodes
- Quality control phenotypes: Summary statistics for the trait(s)
- Field trial analysis: Mixed model analysis of field trial for the trait(s)
- Export field trial results:Stores results in external files
- Generate report:HTML report of results including means and summaries for the trait(s)
- Export means for further analysis: Stores adjusted means in an external file using a format ready to use in a GxE or QTL analysis pipeline
Analysis Options
Some of the nodes have options to control they way an analysis is performed and output that is displayed. To access the options, right-click on a node and select the Settings item from the shortcut menu. The changes to the options are retained during the current session and are saved to the project file.
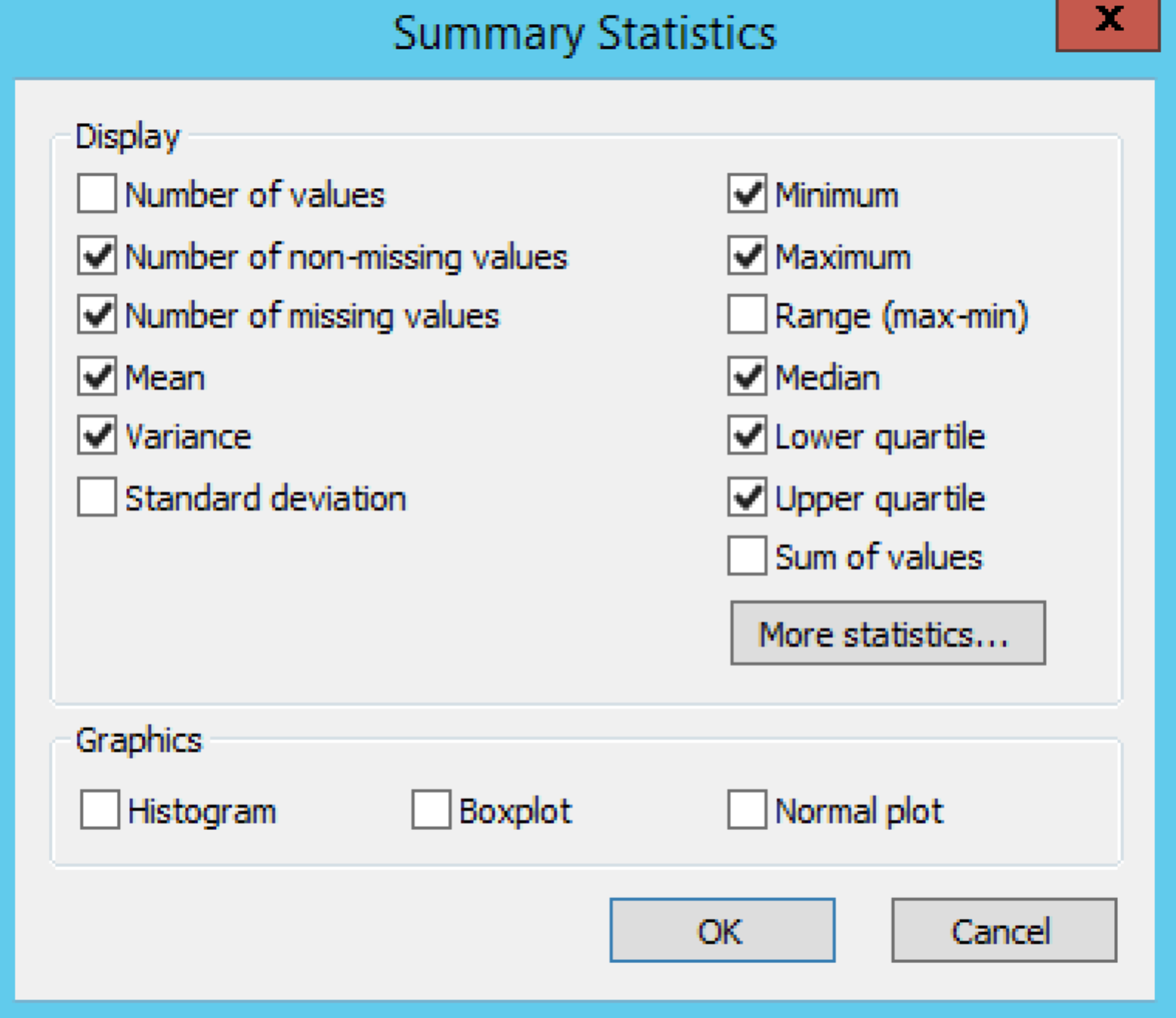
Summary Statistics
Default settings under Quality Control Phenotypes define the summary statistics that are displayed in the output.
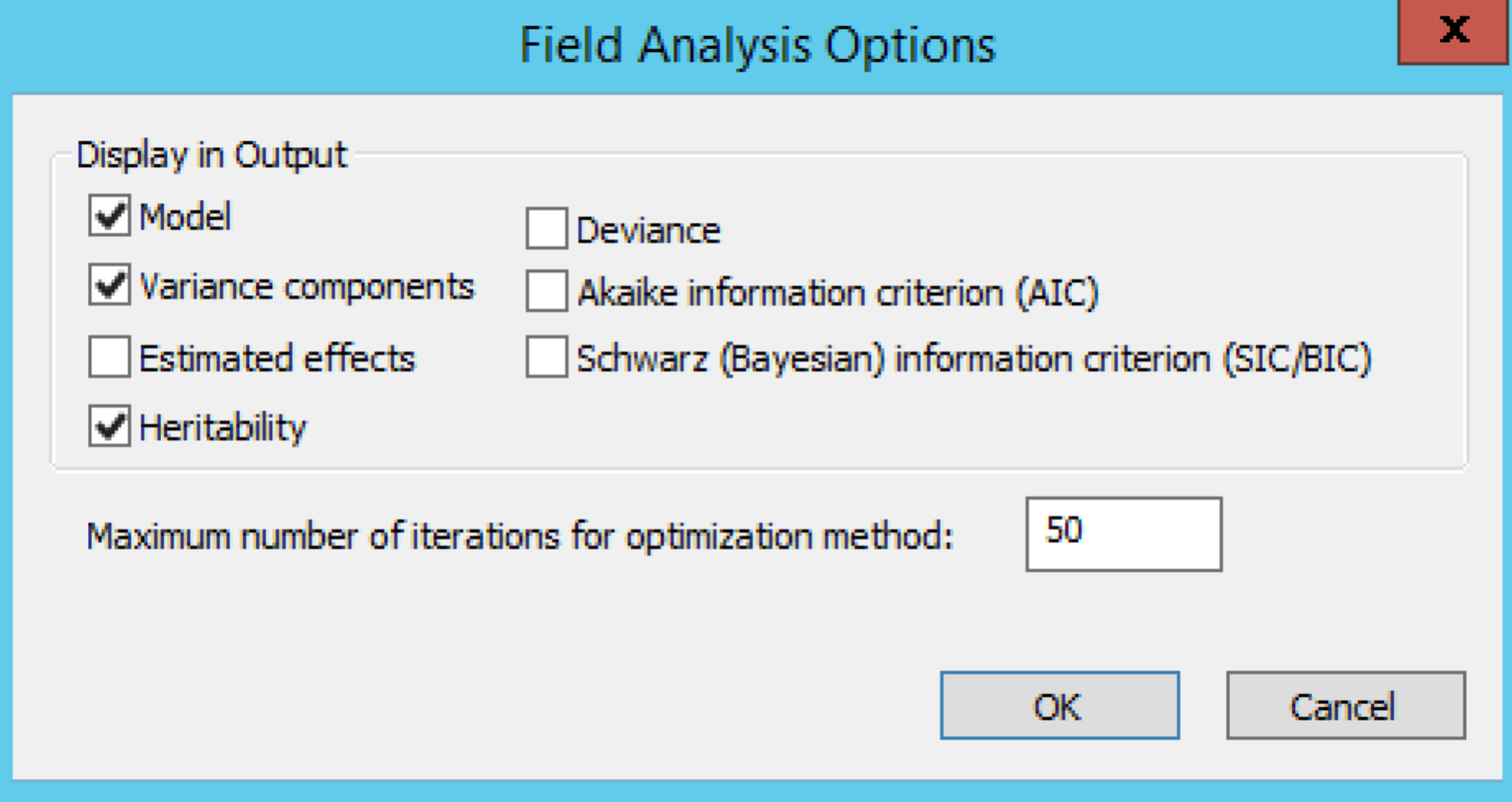
Field Analysis Options
Default settings under Field Trial Analysis define the output and iterations for optimization.
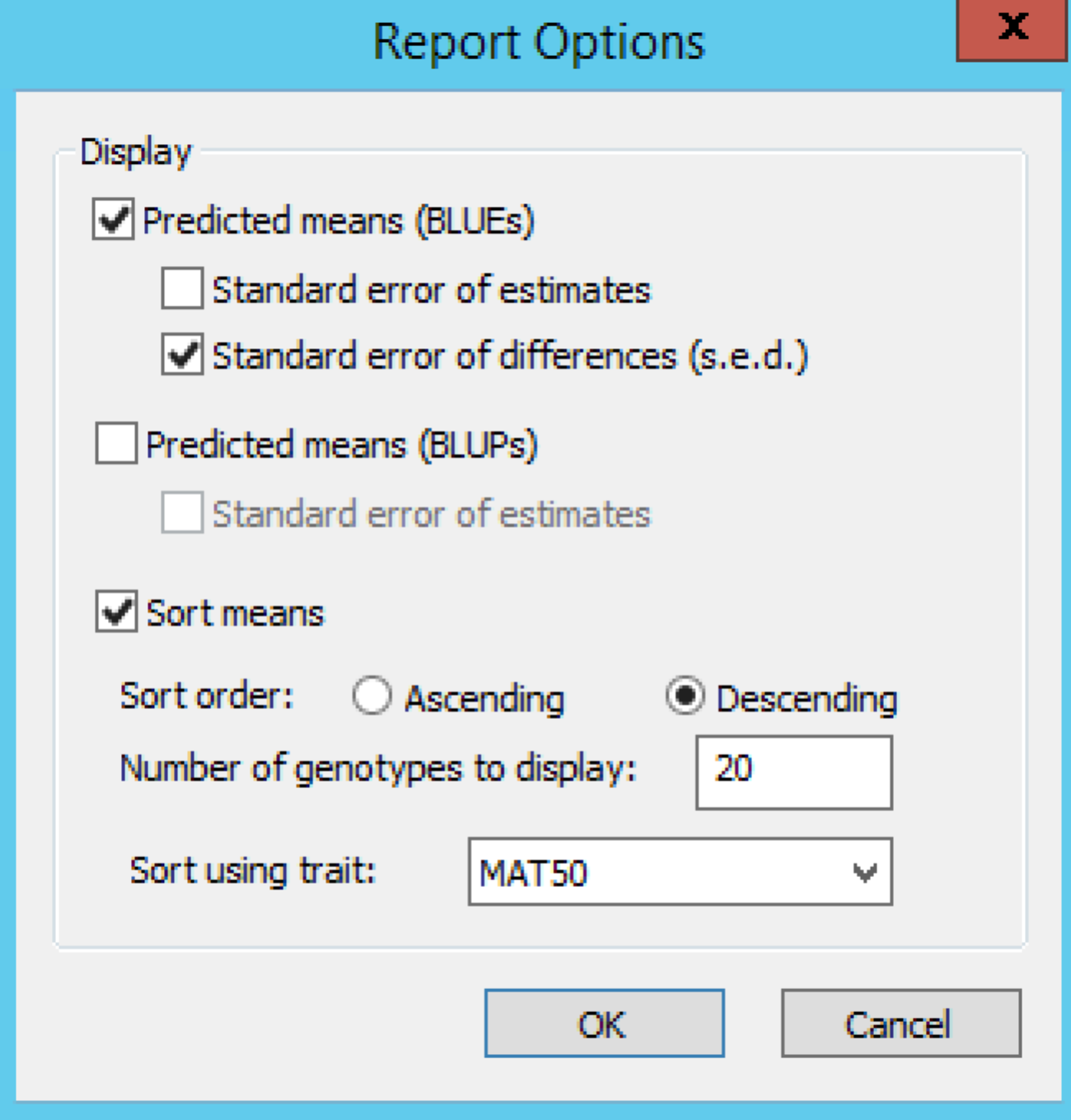
Report Options
Default settings under Generate Report define the reporting options.
Analysis Results
- In this example leave the default settings and run the entire pipeline. Right click the first box and Run Selected Environment Pipelines. When the analysis is complete a popup notifies the user.
Quality Assurance
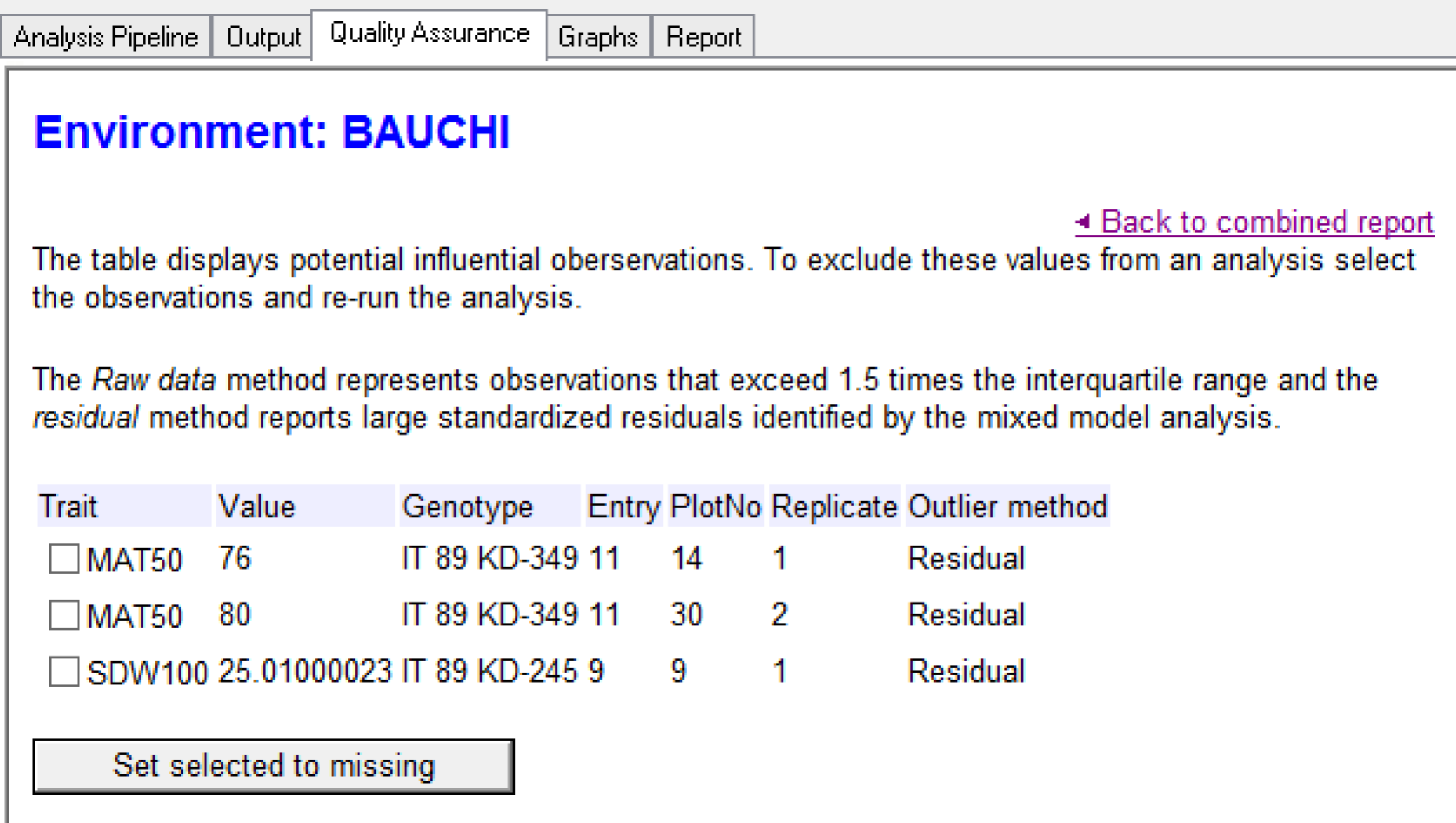
When the analysis pipeline is complete a Quality Assurance tab is generated. The Quality assurance tab displays reports of potentially influential (outlier) values for each location.
Breeding View identifies two types of outliers:
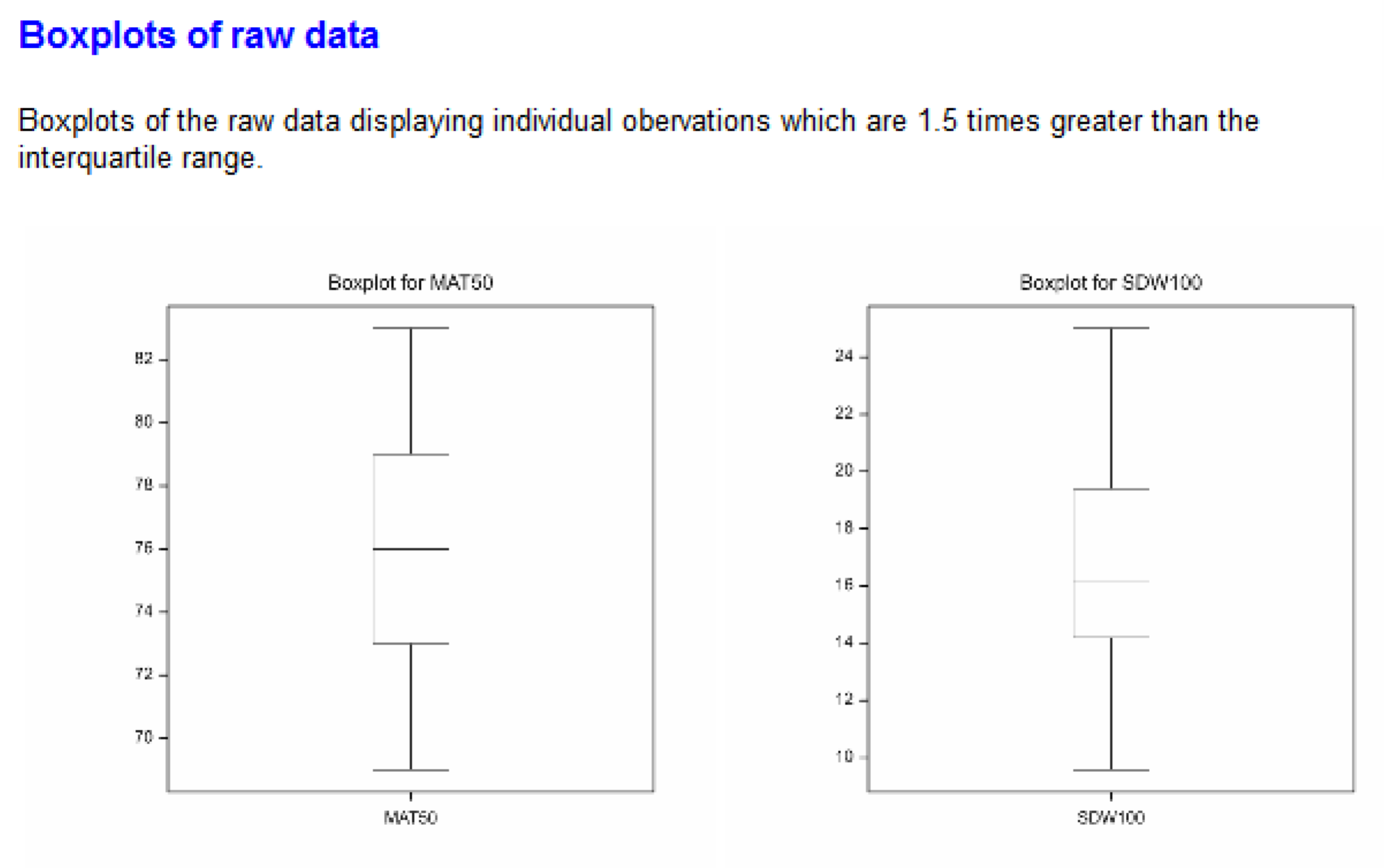
- Raw data outliers are observations that exceed 1.5 times the interquartile range, and can be seen on the accompanying boxplot.
- Residual outliers are observations that have been reported as a large standardized residual by mixed model analysis.
- Select the Bauchi environment to view details.

The Quality Assurance report can be used to change observations to become missing for the analysis. To do this, select the observations to set as missing from the list of traits, and click the Set Selected as Missing. The next time the analysis is run those observations will be excluded from the analysis. For this tutorial, do not exclude any values from the analysis.
Breeding View presents box plots of the variation found in the raw data. Diagnostic plots for the mixed model analysis can be viewed in the Graph or Report tabs
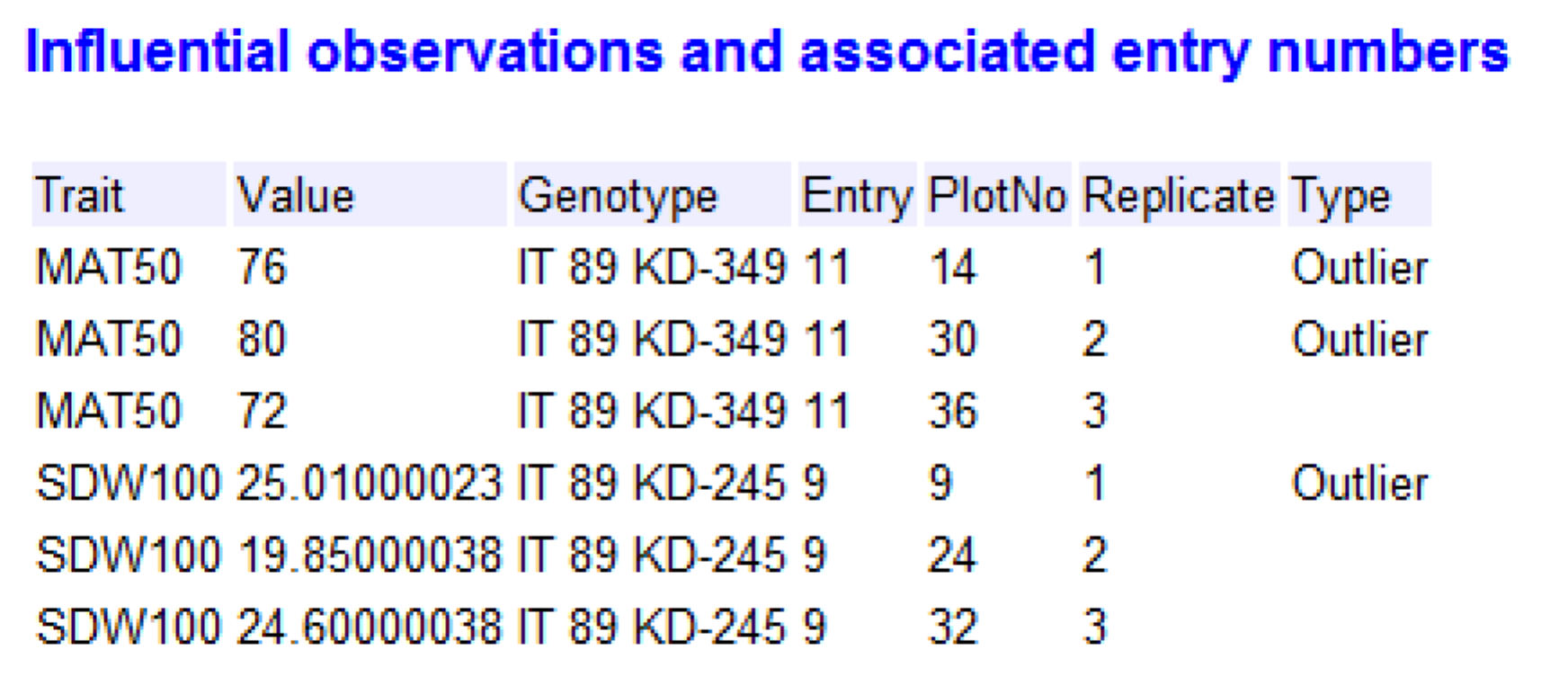
Review the table of entries/genotypes that have potentially influential observations with their associated values, as well as other plots within the field design.
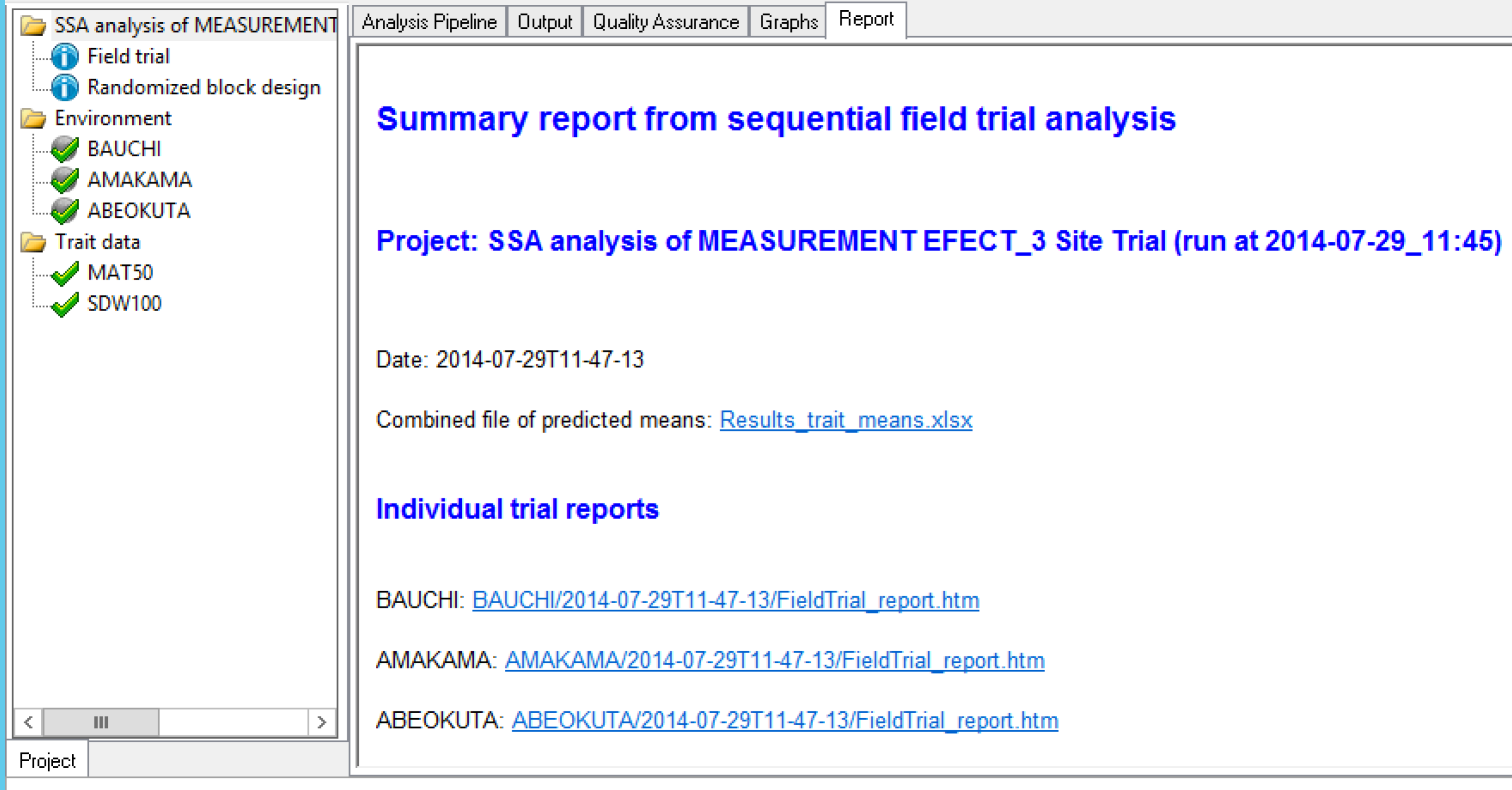
Report
The report tab includes:
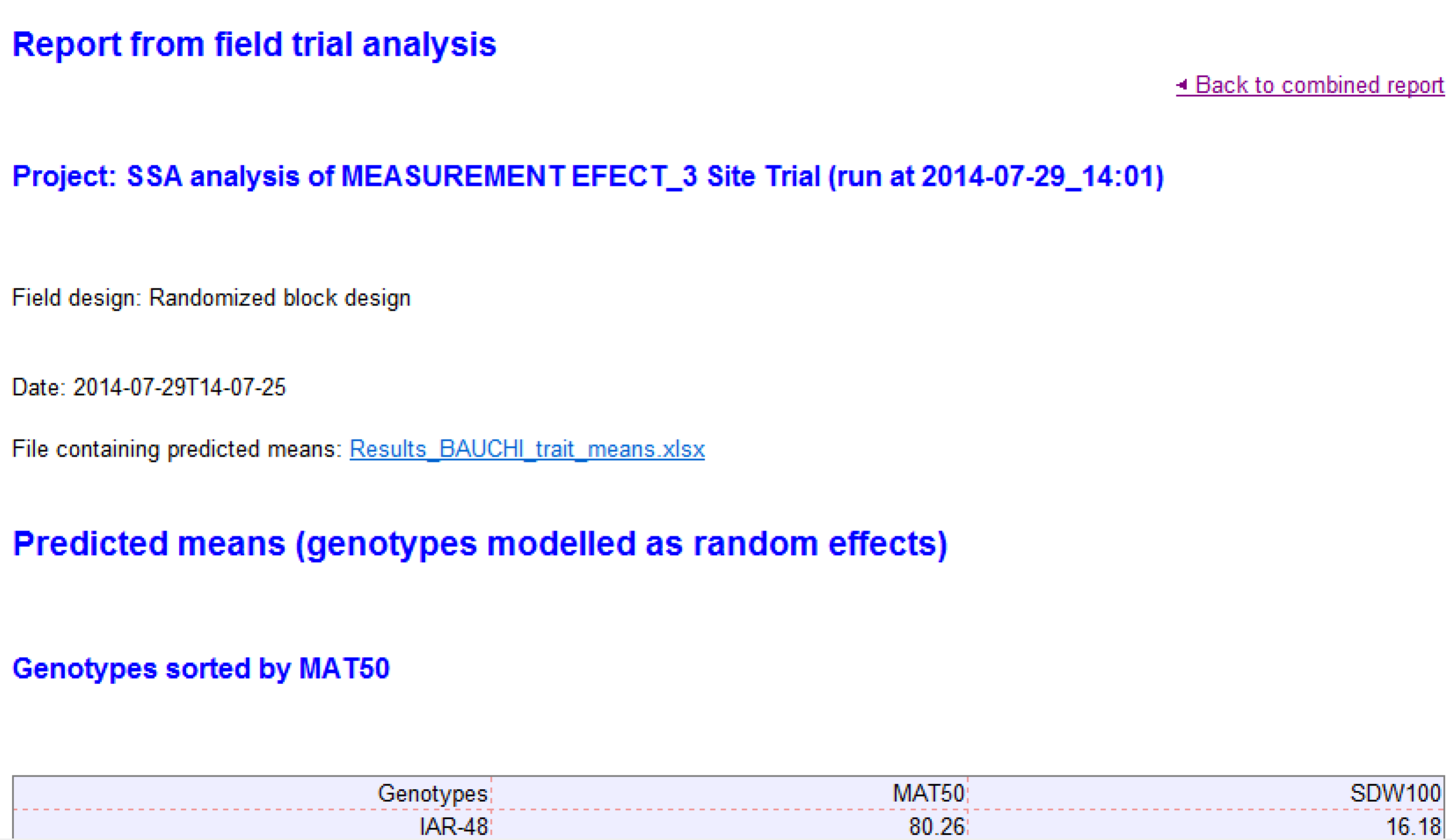
- Combined file of predicted means: Excel file of BLUEs and BLUPs
- Links to individual trial reports
- Heritability Table: Broad-sense mean line heritability, derived from an estimate of the correlation between the genotype BLUPs and their unknown true value (Cullis, Smith & Coombes, 2006).
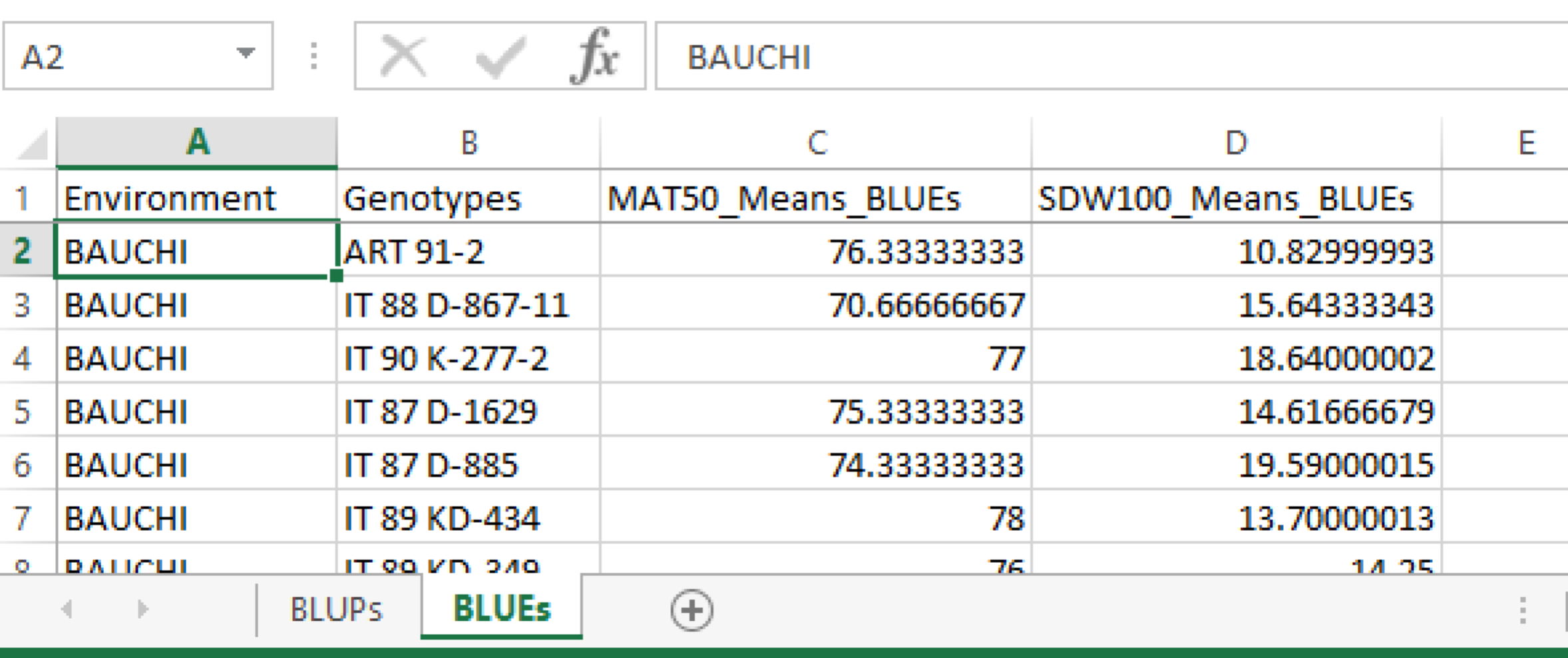
Combined File of Predicted Means
- Open the combined file of predicted means in Excel or other spreadsheet program. The file contains two worksheets with BLUPs and BLUEs.
Individual Trial Reports
- View individual trial reports with summary statistics and diagnostic plots by selecting the location of interest, in this case Bauchi.
Save Analysis Results
When an analysis pipeline is run, the associated files are automatically saved into the BMS workspace folder.
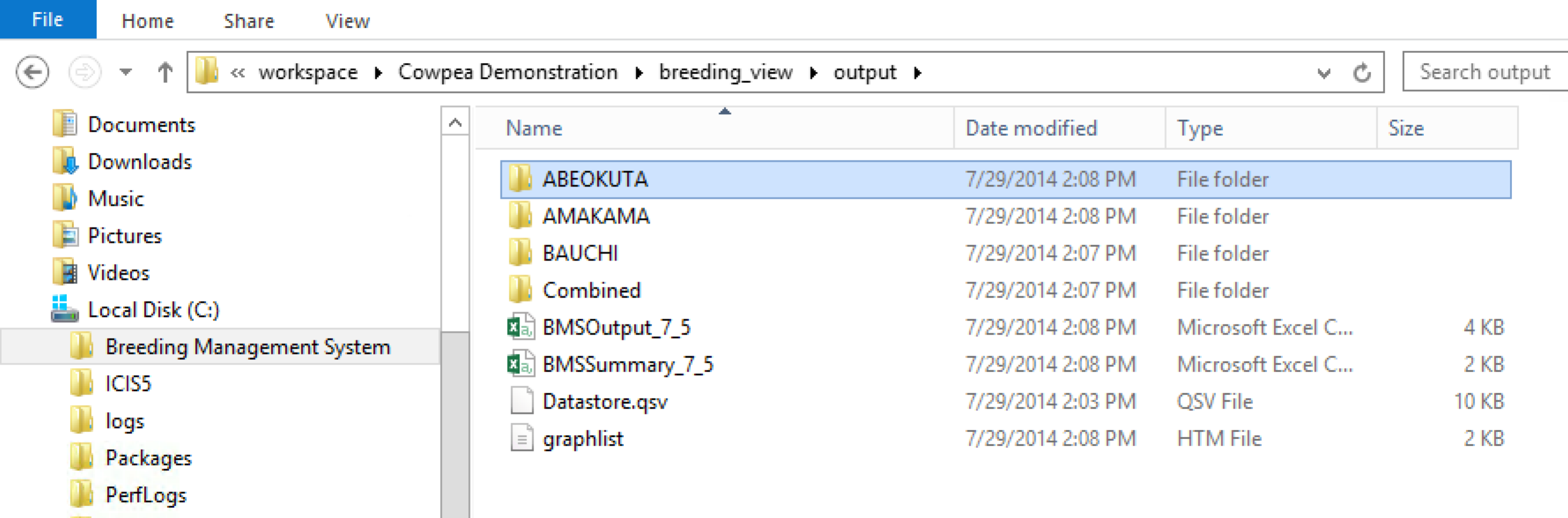
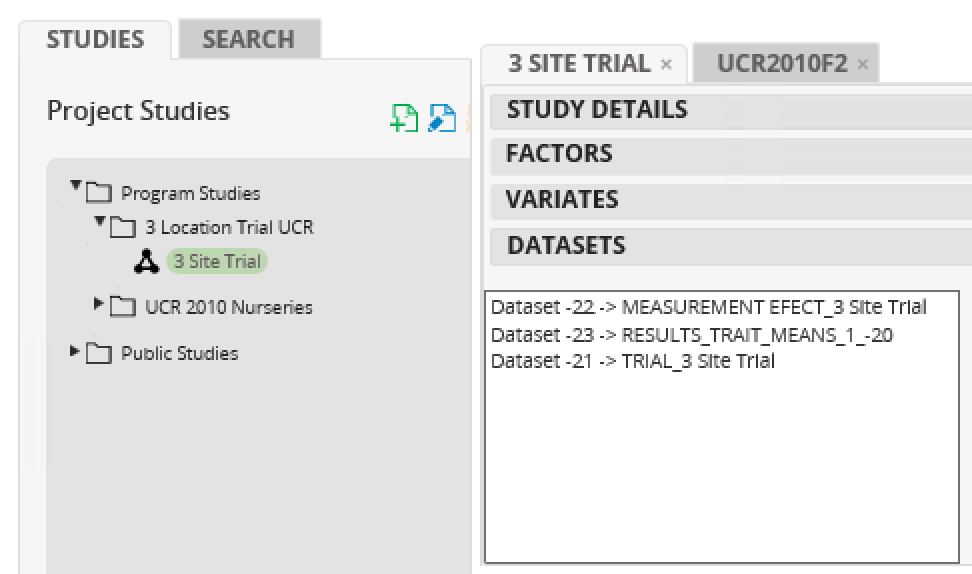
- Upload the results of the analysis to the Workbench database by selecting Upload to the BMS. Once saved to the database, select Browse Studies from the Information Management tools on the Workbench menu to view study data. Notice that the trait means have now been added to the database.
References
Murray, D. Payne, R, & Zhang, Z. (2014) Breeding View, a Visual Tool for Running Analytical Pipelines: User Guide. VSN International Ltd. (.pdf) (Sample data .zip)
Funding & Acknowledgements
The Integrated Breeding Platform (IBP) is jointly funded by: the Bill and Melinda Gates Foundation, the European Commission, United Kingdom's Department for International Development, CGIAR, the Swiss Agency for Development and Cooperation, and the CGIAR Fund Council. Coordinated by the Generation Challenge Program the Integrated Breeding Platform represents a diverse group of partners; including CGIAR Centers, national agricultural research institutes, and universities.
The statistical algorithms in the Breeding View were developed by VSN International Ltd in collaboration with the Biometris group at University of Wageningen. Cowpea ?demonstration data was provided by Jeff Ehlers, Tim Close, Philip Roberts, Bao Lam Huyuh at the University of California Riverside and Issa Drabo at the Institut de l'Environnement et de Recherches Agricoles in Burkina Faso. These data may have been adapted for training purposes. Any misrepresentation of the raw breeding data is the solely the responsibility of the IBP.

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
